




What is NLP?
Natural language processing is a field in linguistics, computer science, and artificial intelligence mainly concerned with the interactions between computers and human language. It deals with analyzing and understanding the languages that humans use on day to day bases in order to interface with computers in both written and spoken contexts using natural human languages instead of computer languages.
Why use PyCaret
PyCaret is an open source machine learning library in Python that allows you to go from preparing your data to deploying your model within minutes using a minimal amount of code, it is essentially a Python wrapper around several machine learning libraries and frameworks such as scikit-learn, CatBoost, Ray and a few more.
It’s simplicity is inspired by the emerging role of data scientist who perform both simple and moderately sophisticated analytical tasks that would previously have required more technical expertise. It should be used mainly by:
- Experienced Data Scientists who want to increase productivity.
- Citizen Data Scientists who prefer a low code machine learning solution.
- Data Science Professionals who want to build rapid prototypes.
- Data Science and Machine Learning students and enthusiasts.
Prerequisites
- Basic knowledge of python
- Basic ML understanding
- Zeal to derive insight from text data
Installation, Data cleaning, importing modules 🛠️
To install pycaret on google collab we need to use the exclamation mark along with the installation command in the notebook.
!pip install pycaret
Once the package has been installed we move further to importing our data and cleaning the data for consumption by our model.
# importing our module
Import pandas as pd
# reading dataset
url = "https://raw.githubusercontent.com/ihamquentin/random-play-projects/main/practice%20folder/CMU-MisCOV19(1).csv"
df = pd.read_csv(url)
df.head(7)

#removing unwanted texts from data
def clean(x):
x = ‘ ‘.join(word for word in x.split() If word[0] != ‘#’ and word[0] != ‘@‘ and word[0:5] != ‘https’ and word[0:2] != ‘RT’ and word[0] != ‘-‘ and word[0] != ‘&’)
return x.replace(‘,’, ‘’)
df[‘text’] = df.apply(lambda x: clean(x.text), axis =1)
df.head(3)

Now we can see that we’ve cleaned our data set and ready to use it in our pycaret NLP model.
#displays interactive visuals.
from pycaret.utils import enable_colab
enable_colab()
#calling pycaret nlp module
from pycaret.nlp import *
exp = setup(data = df, target = 'text', session_id = 123)
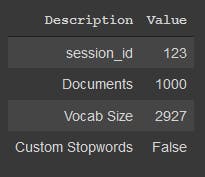
Once the setup executed it prints out an information grid with the following information:
session_id : A random number distributed as a seed in all functions for later reproducibility.
Documents : samples in the dataset
Vocab Size : Size of vocabulary in the corpus after applying all text pre-processing such as removal of stopwords(a word that is automatically omitted from a computer-generated concordance or index) and lemmatization etc.
Creating a topic
A topic model is a type of statistical model for discovering the abstract "topics" that occur in a collection of documents. Topic modeling is a frequently used text-mining tecnique for discovering hidden semantic structures in a text body. In pycaret a topic model is created using create_model() function which takes one mandatory parameter i.e. name of model as a string. This function returns a trained model object.
lda = create_model('lda')
print(lda)

Assigning a model
Now that we have created a topic, we would assign the topic proportions to our dataset to analyze the results, in pycaret this can be done using the assign_model() function.
lda_results = assign_model(lda)
lda_results.head()

plotting model
Pycaret comes with an inbuilt function that can be used to analyze the overall corpus or only specific topics extracted through topic model. To do this we just call the plot_model function in pycaret and it plots our model, it can also be used to analyze the same plots for specific topics. To generate plots at topic level, function requires trained model object to be passed inside i.e
plot_model(lda, plot='tsne')
wrapping up
In this tutorial, we have only covered basics of pycaret.nlp, we have performed several text pre-processing using setup() then we have created a topic model, assigned topics to the dataset and analyzed the. All this was completed in less than 10 commands if we were to re-create the entire experiment without PyCaret would have taken well over 30 lines of code
Let's connect 🖇️
feel free to reach me on: LinkedIn Twitter or check out my Github